人工智能(AI)浪潮席卷全球,其在各行業的應用落地與價值創造有目共睹。經濟學家郝聯峰先生曾多次強調,人工智能的蓬勃發展,離不開一個堅實而廣闊的基礎——大數據。這一觀點深刻地揭示了大數據與人工智能之間密不可分的依存與驅動關系,而作為將兩者有效連接與轉化的關鍵樞紐,人工智能基礎軟件的發展則顯得尤為重要。
一、大數據:人工智能的“燃料”與“訓練場”
郝聯峰指出,人工智能,特別是當前主流的數據驅動型AI(如深度學習),其核心能力——感知、認知、決策與生成——并非憑空產生,而是通過海量、多維度、高質量的數據“喂養”和“訓練”出來的。大數據為人工智能模型提供了學習所需的“原材料”和“經驗”。
- 模型訓練的基礎:無論是圖像識別、自然語言處理,還是智能推薦、預測分析,都需要使用龐大的標注數據集對算法模型進行訓練,使其能夠識別模式、規律。沒有足夠規模和多樣性的數據,模型的準確性和泛化能力將無從談起。
- 性能優化的依據:模型的迭代與優化同樣依賴于數據。通過持續輸入新的數據,可以不斷測試模型的性能,發現其偏差與不足,從而進行針對性的調整與改進,推動AI系統向更高水平演進。
- 場景落地的前提:人工智能要解決具體的商業與社會問題,必須理解特定場景下的數據特征。行業大數據的積累與治理,是AI技術能夠貼合實際、創造價值的前提條件。
因此,大數據在體量、質量、流通速度和處理能力上的每一次進步,都在實質上拓寬了人工智能可能達到的能力邊界。
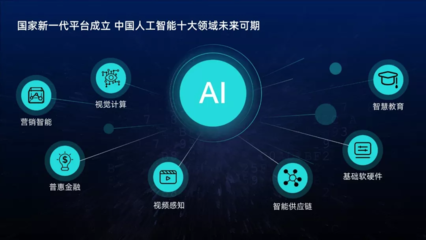
二、人工智能基礎軟件:駕馭數據、賦能智能的“操作系統”
原始的數據洪流本身并不能直接轉化為智能。如何高效地存儲、管理、處理這些數據,并在此基礎上構建、訓練、部署和運維復雜的AI模型,這就需要強大的人工智能基礎軟件作為支撐。郝聯峰所強調的“基礎”,不僅指數據資源,也必然涵蓋將這些資源轉化為生產力的工具與平臺層。
人工智能基礎軟件構成了AI技術棧的核心部分,主要包括:
- 計算框架與平臺:如TensorFlow、PyTorch等,它們提供了構建神經網絡模型的編程接口和底層計算優化,是AI開發者的核心工具。
- 數據處理與治理工具:用于數據的采集、清洗、標注、存儲與管理,確保輸入模型的數據是高質量、可用的。
- 模型開發與訓練平臺:提供從算法選擇、自動化訓練(AutoML)、超參數調優到大規模分布式訓練的一體化環境,降低開發門檻,提升研發效率。
- 模型部署與運維(MLOps)工具:解決訓練好的模型如何高效、穩定、安全地集成到實際生產系統中,并實現持續的監控、更新與管理。
這些基礎軟件的成熟度,直接決定了數據價值被挖掘的深度與廣度,以及AI應用規模化落地的速度和成本。它們是大數據與AI應用之間的“轉換器”和“加速器”。
三、協同共進:構建數據、軟件與智能的良性循環
郝聯峰的觀點啟示我們,大數據、基礎軟件與人工智能應用三者之間形成了一個緊密互動、相互促進的增強循環:
- 數據驅動軟件創新:海量、多元的數據處理需求,不斷挑戰現有基礎軟件的極限,推動其在計算架構、算法效率、系統穩定性等方面持續創新。
- 軟件釋放數據價值:更先進的基礎軟件使得處理更復雜的數據、訓練更龐大的模型成為可能,從而從數據中提煉出更深層次的洞察與更強大的智能。
- 智能應用反哺生態:成功的AI應用會產生新的數據(反饋數據),這些數據回流后又能用于優化模型和軟件,同時驗證軟件平臺的能力,推動整個生態向更高水平發展。
郝聯峰先生關于“大數據是人工智能發展基礎”的論斷,精準地把握了當代AI發展的核心邏輯。我們應在此基礎上進一步認識到,強大的人工智能基礎軟件是夯實這一基礎、激活數據潛能的關鍵工程力量。只有在數據資產建設、基礎軟件研發和行業應用創新三者上協同發力,才能牢牢筑穩人工智能發展的基石,推動我國在全球AI競爭中行穩致遠,讓智能技術更好地造福社會與經濟。